国产第一!阿里 Qwen3.7-Max 旗舰模型发布:全自主完成 35 小时复杂任务
2026-05-20 12:10:23
5 月 20 日消息:阿里巴巴在"2026 阿里云峰会”上,正式发布全新一代千问旗舰模型——Qwen3.7-Max。
在三方机构Arena全球大模型盲测总榜中,Qwen3.7-Max超过Kimi-K2.6、DeepSeek-v4-pro、GLM-5.1,与GPT、Claude、Gemini最强模型接近,位列国产模型第一。
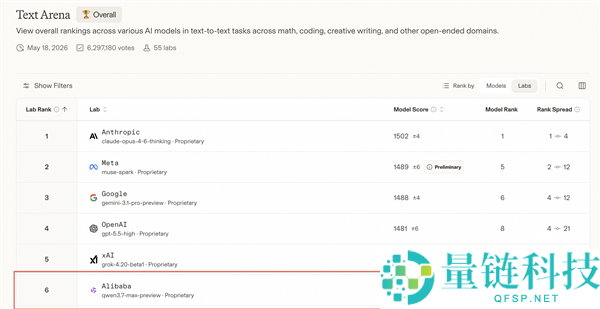
这是千问旗舰模型近三个月内的第三次重大迭代,从3.5到3.6再到3.7,阿里大模型研发节奏明显加速。
Qwen3.7-Max面向智能体(Agent)场景全新设计,在多个核心维度实现突破。
编程方面,在SWE-Pro、SWE-Multilingual等编程智能体测评中均取得领先,Terminal Bench 2.0-Terminus得分69.7,超过DeepSeek-v4-pro-Max和Claude-Opus4.6等。
通用智能体方面,Qwen3.7-Max在MCP-Atlas、MCP-Mark、Skillbench等现实能力测试中表现优异,超越GLM5.1、Kimi-K2.6等模型,创下国产新高。
推理方面,在GPQA Diamond、HLE、HMMT 2026 Feb等推理核心测评中超越Claude-Opus4.6及所有国产模型。
通用能力上,Qwen3.7-Max在指令遵循IFBench评测中得分79.1分创下新高,多语言评测WMT24++、MAXIFE中同样领先。
实战任务测试中,在一个模型训练时从未接触过的全新硬件平台平头哥真武M890芯片上,Qwen3.7-Max在没有任何性能分析数据、硬件文档或新架构的示例内核情况下,从空白工作空间出发,自主完成了推理内核优化任务。
整个过程持续35小时,模型独立进行了432次内核评估和1158次工具调用,完全自主地完成了编写、编译、性能分析与迭代改进的全流程。
最终优化后的推理内核较SGLang Triton官方参考实现取得了10倍加速。
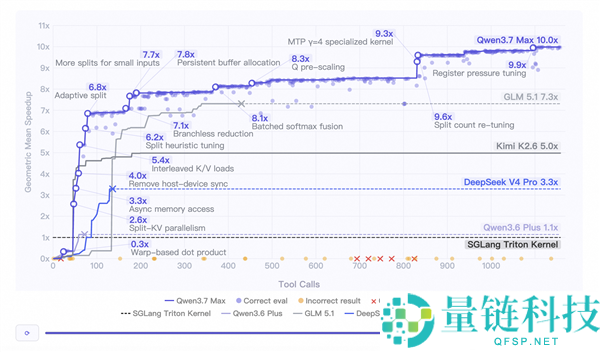
测试轨迹显示,模型在独立运行超过30小时后仍能发现有效优化点,甚至主动发起了一次关键的架构重设计。
在Agent能力方面,Qwen3.7-Max展现出跨框架泛化能力,在Claude Code、OpenClaw、Qwen Code等框架下均能稳定发挥。
通过MCP集成和多智能体协作,该模型在办公自动化基准SpreadSheetBench-v1上斩获87分,处于顶尖水平。
阿里云表示,Qwen3.7-Max API即将上线百炼平台,后续还将推出Qwen3.7-Plus等版本,覆盖从编程智能体到视觉智能体的全场景需求。
 相关阅读
相关阅读
-
业内首家!佳能打印机官宣接入米家 App,首批 61 款支持手机远程打印深度解读 2026-05-20 12:06:18

-
美图秀秀帮助与反馈在哪里?美图秀秀帮助与反馈查看方法资讯百科 2026-05-20 12:03:10
-
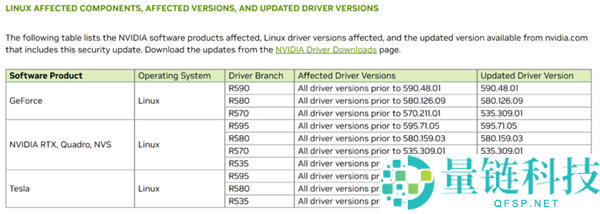
NVIDIA 驱动曝多个高危漏洞:全系显卡中招,官方紧急呼吁立刻更新金融科技前沿 2026-05-20 12:00:52
-
影石发布 Mic Pro 无线麦克风:首创黑色自定义墨水屏,528 元起深度解读 2026-05-20 11:56:40
-
电信运营商网上营业厅新国标:严禁使用 0 元、收费及不限量等表述金融科技前沿 2026-05-20 11:55:01
-
Lighter(LIT) 币详解:未来潜力、空投领取攻略及价格预测区块链快讯 2026-05-20 11:51:34

-
绝版回归!苹果官网 448 元 iPhone 握把支架重新上架,首销秒罄配件再售深度解读 2026-05-20 11:51:08

-
小米汽车 CTO 胡峥楠祝贺任周灿:坚守十余年终获世界认可金融科技前沿 2026-05-20 11:48:41

-
宋雨琦代言 OPPO Reno16 系列:四色外观正式发布,颜值新标杆深度解读 2026-05-20 11:46:22
-
猫耳fm怎么查看个人收听记录?猫耳fm查看个人收听记录教程资讯百科 2026-05-20 11:46:00








