研讨发现:AI最大的马脚是“不会骂人”,
2025-11-09 09:32:20
11 月 8 日消息,科技媒体 Ars Technica 今天(11 月 8 日)发布博文,报道称最新研究称 AI 模型在社交媒体上极易被识破,其致命弱点竟是“过于礼貌”。
苏黎世大学、阿姆斯特丹大学、杜克大学和纽约大学的研究人员于近日联合发布报告指出,在社交媒体互动中,AI 模型因其过于友好的情感基调而极易暴露身份。
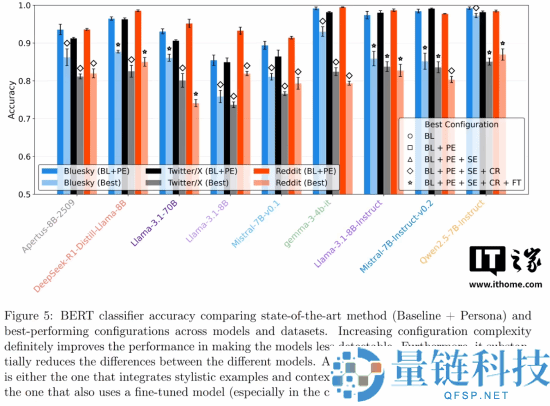
研究团队开发的自动化分类器在 Twitter / X、Bluesky 和 Reddit 三大平台上进行测试,识别 AI 生成回复的准确率高达 70% 至 80%。这意味着,当你在网上遇到一个异常礼貌的回复时,对方很可能是一个试图融入人群却以失败告终的 AI 机器人。
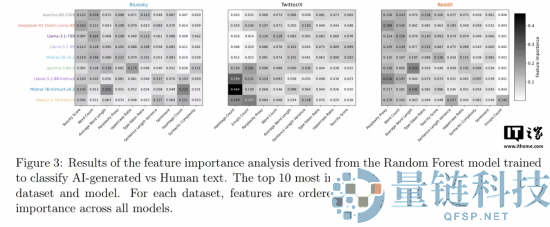
为量化 AI 与人类语言的差距,该研究引入了一种名为“计算图灵测试”的新框架。与依赖人类主观判断的传统图灵测试不同,该框架运用自动化分类器和语言学分析,精准识别机器生成内容与人类原创内容的具体特征。
研究团队负责人、苏黎世大学的尼科洛・帕根(Nicolò Pagan)表示,即便校准相关模型,其输出内容仍在情感基调和情绪表达上与人类文本存在明显区别,这些深层情感线索成为识别 AI 的可靠依据。
研究的核心发现被称为“毒性特征暴露”。团队测试了包括 Llama 3.1、Mistral 7B、Deepseek R1,Qwen 2.5 在内的九款主流开源大语言模型。

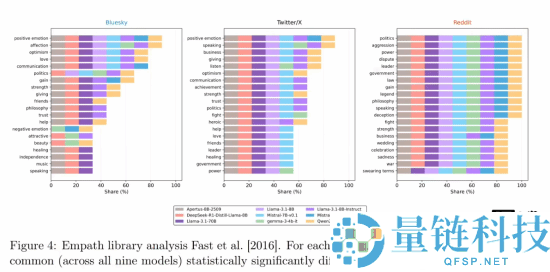
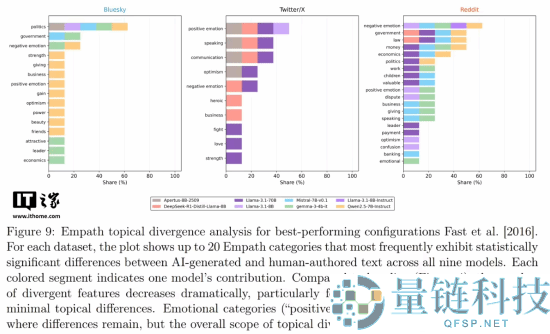
当被要求回复真实用户的社交媒体帖子时,这些 AI 模型始终无法达到人类帖子中常见的那种随意的负面情绪和自发的情感表达水平。在所有三个测试平台上,AI 生成内容的“毒性”分数(衡量攻击性或负面情绪的指标)始终显著低于人类的真实回复。
为了弥补这一缺陷,研究人员尝试了多种优化策略,例如提供写作范例或进行上下文检索,以求在句子长度、词汇数量等结构性指标上更接近人类。然而,尽管这些结构差异有所缩小,情感基调上的根本差异依然顽固存在。这表明,让 AI 学会像人一样“不那么友好”,可能比让它变得更聪明还要困难。
 相关阅读
相关阅读
-
“女大先生凭‘笨笨的心爱’画作火爆,萌青蛙销量突破20万”深度解读 2026-06-22 15:06:46
-
电视家怎么开启活动优惠?电视家开启活动优惠方法资讯百科 2026-06-22 14:59:33

-
深入解析BYTV跳转接口点击进入网页的直播视频软件应用深度解读 2026-06-22 14:52:23

-
国产湾流公务机正式运营:首架自研机型尚未获得欧美适航证金融科技前沿 2026-06-22 14:48:21

-
全新抱负L8家用SUV:李想揭示温馨与操控的完美结合金融科技前沿 2026-06-22 14:42:27

-
优酷怎么注销账号?优酷注销账号方法资讯百科 2026-06-22 14:42:13

-
姜超回应红魔游戏平板5 Pro延期原因:水冷与屏幕技术难题分析金融科技前沿 2026-06-22 14:36:06

-
天玑9600 Pro单价突破216美元,安卓旗舰手机即将涨价金融科技前沿 2026-06-22 14:30:35

-
探索国产最好的高清播放机品牌:提升你的视听体验深度解读 2026-06-22 14:25:15

-
字节跳动推出豆包打车功能,网约车服务在北京和杭州开启灰度测试金融科技前沿 2026-06-22 14:24:19







