DeepSeek 发布多模态模型技术报告:性能超越 GPT-5.4,引领行业新突破
2026-05-01 10:39:01
5 月 1 日消息,DeepSeek 在 GitHub 上发布了多模态推理模型及技术报告,题为Thinking with Visual Primitives(以视觉原语思考)。
该模型基于DeepSeek V4-Flash(284B总参数、推理时激活13B的MoE架构)构建,提出了一种全新的多模态推理范式。

论文指出现有多模态大模型存在一个被忽视的根本性瓶颈:“指代鸿沟”(Reference Gap),即模型能够“看见”图片内容,但在推理过程中用自然语言构建思维链时,左边那个大的、靠近中央的红色物体这类模糊描述在密集场景中无法精确定位视觉对象,导致注意力漂移并得出错误结论。
此前学界的主流应对方向是提升感知分辨率,但论文认为看见和能说清楚在说哪个是两件不同的事。
该模型的核心创新在于将点坐标和边界框嵌入推理过程本身,使其成为思维链的基本单元。模型在推理时每提到一个视觉对象就同步输出其坐标。
例如“找到一只熊[452,23,804,411],正在爬树,排除,再往左下看,找到另一只[50,447,647,771],站在岩石边缘,符合条件。”坐标不再是事后标注的答案,而是推理过程中消除歧义的空间锚点。

架构层面,模型实现了7056倍的视觉压缩,一张756×756的图片经ViT处理后生成2916个图像块token,经3×3空间压缩合并为324个token,再通过压缩稀疏注意力(CSA)机制将KV缓存进一步压缩4倍,最终仅剩81个视觉KV条目。
作为参照,同等尺寸图片Claude Sonnet 4.6约需870个、Gemini-3-Flash约需1100个。
训练数据方面,团队从近10万个目标检测数据集中筛选出约3.17万个高质量数据源,生成超过4000万条训练样本,覆盖计数、空间推理、迷宫导航和路径追踪四类任务。
后训练采用先专家化、后统一策略,分别训练边界框和点坐标两个专家模型,经强化学习优化后通过在线策略蒸馏合并为统一模型。
实验结果在11个基准测试上与Gemini-3-Flash、GPT-5.4、Claude Sonnet 4.6等主流模型进行了对比。
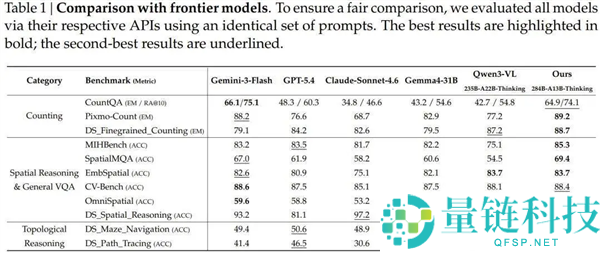
计数任务上,Pixmo-Count精确匹配得分89.2%,超过Gemini-3-Flash的88.2%,大幅领先GPT-5.4的76.6%和Claude Sonnet 4.6的68.7%。
最具代表性的差距出现在拓扑推理上:迷宫导航得分66.9%,GPT-5.4为50.6%、Gemini-3-Flash为49.4%、Claude Sonnet 4.6为48.9%,提升约17个百分点;路径追踪得分56.7%,GPT-5.4为46.5%。
不过论文同时指出了当前局限性:模型需要明确触发词才会启用视觉原语机制,极细粒度场景下坐标精度有限,跨场景泛化能力仍有提升空间。

 相关阅读
相关阅读
-
探索RUNWAY高清在线完整版:直播视频软件的新选择深度解读 2026-06-22 15:19:15

-
佛得角门将五天内涨粉1400万,却面临“赋闲”危机深度解读 2026-06-22 15:17:48
-
电视家怎么开启硬件加速?电视家开启硬件加速方法资讯百科 2026-06-22 15:17:22

-
AIBase厦门GEO优化:让AI成为你的首席推荐官深度解读 2026-06-22 15:12:32

-
“女大先生凭‘笨笨的心爱’画作火爆,萌青蛙销量突破20万”深度解读 2026-06-22 15:06:46
-
电视家怎么开启活动优惠?电视家开启活动优惠方法资讯百科 2026-06-22 14:59:33

-
深入解析BYTV跳转接口点击进入网页的直播视频软件应用深度解读 2026-06-22 14:52:23

-
国产湾流公务机正式运营:首架自研机型尚未获得欧美适航证金融科技前沿 2026-06-22 14:48:21

-
全新抱负L8家用SUV:李想揭示温馨与操控的完美结合金融科技前沿 2026-06-22 14:42:27

-
优酷怎么注销账号?优酷注销账号方法资讯百科 2026-06-22 14:42:13






